(This article was first published on Getting Genetics Done, and kindly contributed to R-bloggers)
Automatically Archiving Twitter Results
Ever since Twitter gamed its own API and killed off great services like IFTTT triggers, I've been looking for a way to automatically archive tweets containing certain search terms of interest to me. Twitter's built-in search is limited, and I wanted to archive interesting tweets for future reference and to start playing around with some basic text / trend analysis.
Enter t - the twitter command-line interface. t is a command-line power tool for doing all sorts of powerful Twitter queries using the command line. See t's documentation for examples.
I wrote this script that uses the t utility to search Twitter separately for a set of specified keywords, and append those results to a file. The comments at the end of the script also show you how to commit changes to a git repository, push to GitHub, and automate the entire process to run twice a day with a cron job. Here's the code as of May 14, 2013:
Ever since Twitter gamed its own API and killed off great services like IFTTT triggers, I've been looking for a way to automatically archive tweets containing certain search terms of interest to me. Twitter's built-in search is limited, and I wanted to archive interesting tweets for future reference and to start playing around with some basic text / trend analysis.
Enter t - the twitter command-line interface. t is a command-line power tool for doing all sorts of powerful Twitter queries using the command line. See t's documentation for examples.
I wrote this script that uses the t utility to search Twitter separately for a set of specified keywords, and append those results to a file. The comments at the end of the script also show you how to commit changes to a git repository, push to GitHub, and automate the entire process to run twice a day with a cron job. Here's the code as of May 14, 2013:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
|
That script, and results for searching for "bioinformatics", "metagenomics", "#rstats", "rna-seq", and "#bog13" (the Biology of Genomes 2013 meeting) are all in the GitHub repository below. (Please note that these results update dynamically, and searching Twitter at any point could possibly result in returning some unsavory Tweets.)
https://github.com/stephenturner/twitterchive
Analyzing Tweets using R
You'll also find an analysis subdirectory, containing some R code to produce barplots showing the number of tweets per day over the last month, frequency of tweets by hour of the day, the most used hashtags within a search, the most prolific tweeters, and a ubiquitous word cloud. Much of this code is inspired by Neil Saunders's analysis of Tweets from ISMB 2012. Here's the code as of May 14, 2013:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
|
Also in that analysis directory you'll see periodically updated plots for the results of the queries above.
Analyzing Tweets mentioning "bioinformatics"
Using the bioinformatics query, here are the number of tweets per day over the last month:

Here is the frequency of "bioinformatics" tweets by hour:

Here are the most used hashtags (other than #bioinformatics):

Here are the most prolific bioinformatics Tweeps:

Here's a wordcloud for all the bioinformatics Tweets since March:

Analyzing Tweets mentioning "#bog13"
The 2013 CSHL Biology of Genomes Meeting took place May 7-11, 2013. I searched and archived Tweets mentioning #bog13 from May 1 through May 14 using this script. You'll notice in the code above that I'm no longer archiving this hashtag. I probably need a better way to temporarily add keywords to the search, but I haven't gotten there yet.
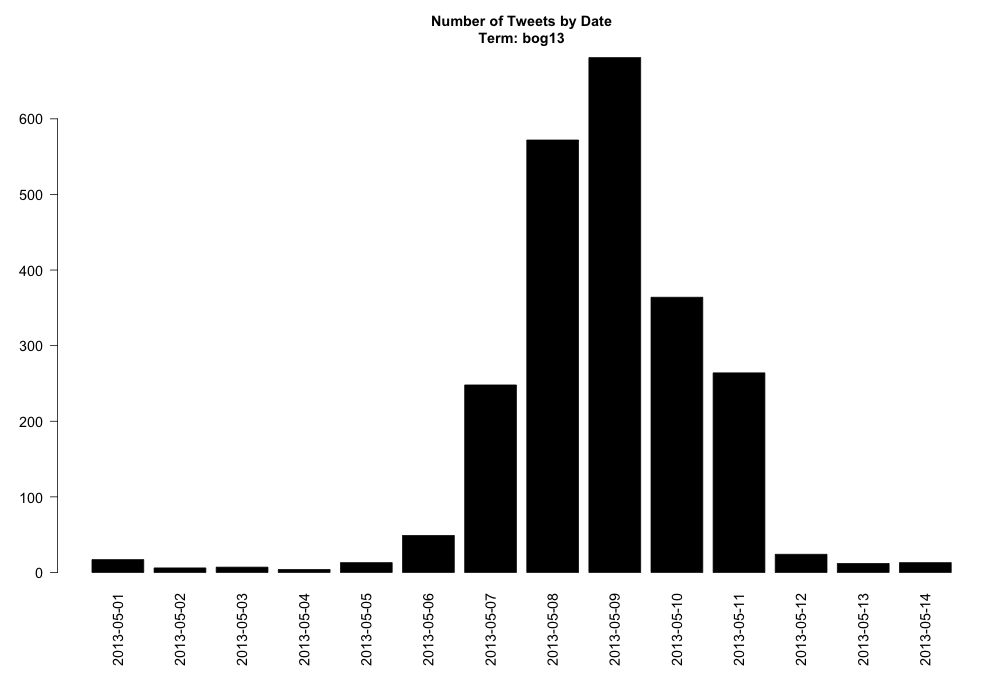
Here are the number of Tweets per day during that period. Tweets clearly peaked a couple days into the meeting, with follow-up commentary trailing off quickly after the meeting ended.
The 2013 CSHL Biology of Genomes Meeting took place May 7-11, 2013. I searched and archived Tweets mentioning #bog13 from May 1 through May 14 using this script. You'll notice in the code above that I'm no longer archiving this hashtag. I probably need a better way to temporarily add keywords to the search, but I haven't gotten there yet.
Here are the number of Tweets per day during that period. Tweets clearly peaked a couple days into the meeting, with follow-up commentary trailing off quickly after the meeting ended.
Here is the frequency frequency of Tweets by hour, clearly bimodal:

Top hashtags (other than #bog13). Interestingly #bog14 was the most highly used hashtag, so I'm guessing lots of folks are looking forward to next years' meeting. Also, #ashg12 got lots of mentions, presumably because someone presented updated work from last years' ASHG meeting.

Here were the most prolific Tweeps - many of the usual suspects here, as well as a few new ones (new to me at least):

And finally, the requisite wordcloud:

More analysis
If you look in the analysis directory of the repo you'll find plots like these for other keywords (#rstats, metagenomics, rna-seq, and others to come). I would also like to do some sentiment analysis as Neil did in the ISMB post referenced above, but the sentiment package has since been removed from CRAN. I hear there are other packages for polarity analysis, but I haven't yet figured out how to use them. I've given you the code to do the mundane stuff (parsing the fixed-width files from t, for starters). I'd love to see someone take a stab at some further text mining / polarity / sentiment analysis!
twitterchive - archive and analyze results from a Twitter search








0 comments:
Post a Comment